El sistema musculoesquelético del cuerpo humano funciona porque hay un esqueleto debajo. Sin él, los músculos tirarían en direcciones contradictorias y el conjunto colapsaría sobre sí mismo. Los stacks modernos de datos e IA tienen exactamente ese problema: muchos músculos —Pydantic, JSON Schema, SQL, GraphQL, RDF— tirando sin hueso debajo. LinkML propone ese hueso.
El problema de fondo: cuatro versiones del mismo dato
Si has trabajado en cualquier arquitectura medianamente seria en los últimos años, esto te va a sonar. Tienes una entidad —pongamos Cliente— y termina viviendo en cuatro sitios distintos:
- Una clase Pydantic en el backend para validar entrada.
- Un JSON Schema en la documentación de tu API y en las definiciones de tools MCP.
- Un SQL DDL en la base de datos.
- Y, si tienes mala suerte, un vocabulario semántico (RDF, OWL, JSON-LD) para algún consorcio o cliente que exige interoperabilidad.
Las cuatro versiones empiezan iguales y, al sexto mes, han divergido. Alguien renombró un campo en Pydantic y olvidó actualizar el DDL. La tool MCP devuelve un JSON que el agente downstream no sabe parsear porque el esquema está desactualizado. Es entropía pura: el sistema tiende al desorden si no inviertes energía constante en mantenerlo alineado.
Es como un cuerpo cuyos huesos crecen a ritmos distintos. Acaba siendo inviable.
¿Qué es LinkML, en una frase?
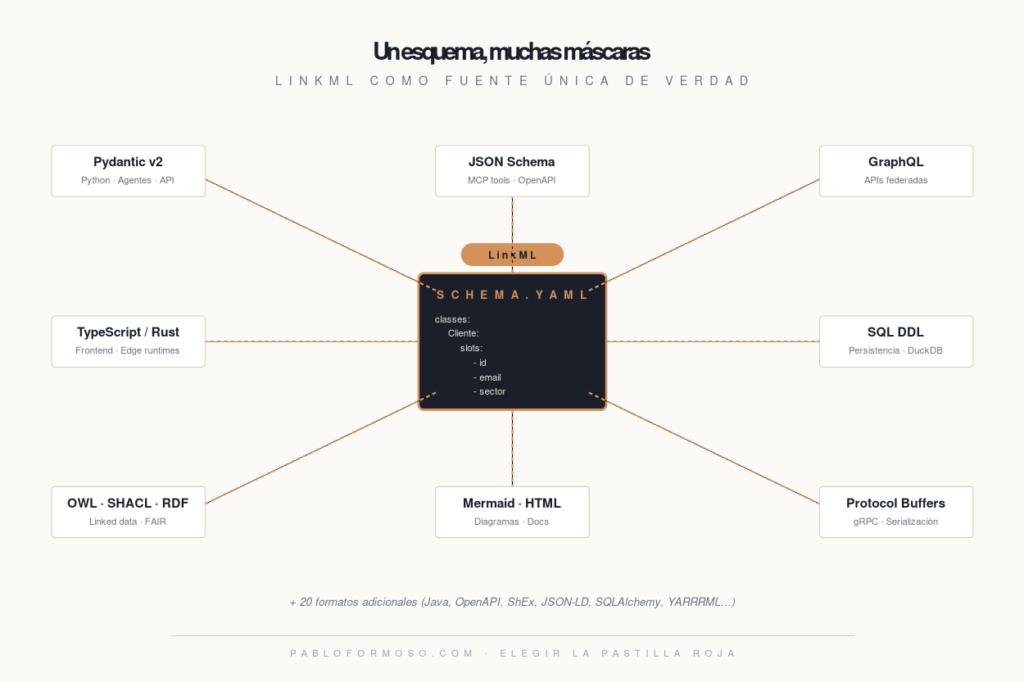
LinkML (Linked data Modeling Language) es un lenguaje declarativo basado en YAML donde defines tu modelo una sola vez y se compila a más de 30 formatos: Pydantic, JSON Schema, SQL DDL, GraphQL, Protocol Buffers, TypeScript, Java, Rust, OWL, SHACL, JSON-LD, Mermaid diagrams, docs HTML… la lista no termina ahí.
Es el esqueleto compartido. Los músculos siguen siendo los mismos —cada lenguaje, cada base de datos, cada API— pero ahora cuelgan de algo coherente.
De dónde viene esto (y por qué importa)
LinkML no nace ayer en una startup con demo en Y Combinator. Viene del Lawrence Berkeley National Laboratory y de la Monarch Initiative, una red de proyectos biomédicos federados que llevan años obsesionados con un problema muy concreto: hacer que cien laboratorios distintos publiquen datos que se puedan combinar sin que cada combinación cueste un mes de trabajo humano.
Pero —y esto es lo interesante— ha trascendido su origen biomédico. Hoy lo usan:
- ENTSO-E (la red eléctrica europea).
- NFDI (la infraestructura nacional de investigación de Alemania).
- NIH Bridge2AI, iSamples, Alliance of Genome Resources y un largo etcétera.
Y la publicación de referencia —Moxon et al., «LinkML: an open data modeling framework»— acaba de salir en GigaScience 2026. No es un proyecto en hibernación: el último commit es de hace 24 horas.
Licencia Apache-2.0 en el core, CC0 en el metamodelo. Todo comercialmente usable sin fricciones. Por si te lo estás preguntando.
Cómo funciona: una sola fuente de verdad
Escribes algo así (YAML, legible incluso para un product manager con buena voluntad):
classes:
Cliente:
description: Una persona o entidad que compra
slots:
- id
- nombre
- email
- sector
slots:
id:
identifier: true
range: string
email:
range: string
pattern: "^\\S+@\\S+\\.\\S+$"
sector:
range: SectorEnum
enums:
SectorEnum:
permissible_values:
energia:
sanidad:
industria:Y desde ese YAML generas, con un comando, las versiones equivalentes en cada formato que necesites. Cambias un campo en el YAML, recompilas, y todas las versiones quedan sincronizadas. Una verdad, muchas máscaras.
La pieza que cambia el juego para los que trabajamos con LLM: OntoGPT
Aquí es donde para mí esto se pone interesante de verdad.
OntoGPT —de Monarch Initiative, BSD-3, 809 estrellas en GitHub— implementa un método llamado SPIRES (Structured Prompt Interrogation and Recursive Extraction of Semantics). El truco es elegante: usas tu esquema LinkML como contrato de extracción. Le das al LLM un texto libre y le pides que extraiga información estructurada conforme a ese esquema. La salida se valida automáticamente contra el contrato. Si el modelo alucina un campo que no existe, se descarta.
Y lo mejor: soporta modelos abiertos vía ollama (Qwen, Llama, Mistral). Es decir, todo el pipeline puede correr on-premise, dentro de tu propio DGX Spark o el hardware que tengas, sin tocar APIs externas. Si te preocupa la soberanía sobre tus datos —y a mí cada día me preocupa más—, esto es relevante.
Es básicamente lo que muchos equipos están reimplementando a mano con Pydantic + Instructor + parsers ad-hoc de LangChain. Solo que aquí, además, el esquema es portable: lo pueden consumir también tu API, tu base de datos y tu pipeline de docs.
Dónde encaja en una arquitectura agéntica moderna
Pensemos en un stack típico hoy: LangGraph orquestando agentes, MCP tools para acciones externas, RAG para contexto, modelos on-premise para inferencia, y un par de APIs downstream con su Pydantic.
Cada uno de esos componentes habla de las mismas entidades —clientes, documentos, eventos— pero cada uno tiene su propia representación. Y cada cambio se propaga como un dolor distribuido por todo el sistema.
LinkML te permite tener un único contrato canónico que se compila a:
- Pydantic para los agentes y el estado de LangGraph.
- JSON Schema para las definiciones de tools MCP.
- SQL DDL para la persistencia.
- JSON-LD u OWL si en algún momento expones los datos como linked data (o si un cliente del sector público te lo exige por compliance).
El cuerpo deja de pelearse consigo mismo.
El ángulo distópico: la otra cara
Voy a ser honesto con la parte oscura, porque siempre la hay.
Imagínate un futuro donde todo está descrito por un esquema formal. Cada interacción humana, cada decisión, cada concepto. Suena a sueño racionalista —y de hecho lo es— pero también suena a control absoluto. Si quien define el esqueleto eres tú, organizas el cuerpo. Si lo define un consorcio cerrado, lo organiza para sus intereses. La interoperabilidad puede ser libertad o puede ser captura, dependiendo de quién sostenga el bolígrafo.
LinkML, por ser abierto, Apache-2.0 y con adopción europea, está hoy en el lado luminoso. Pero la herramienta es neutral. Lo que se haga con ella, no. Conviene tenerlo presente cuando pensamos en estándares de datos para la próxima década.
Cuándo usarlo y cuándo no
No es una bala de plata. Mi heurística práctica:
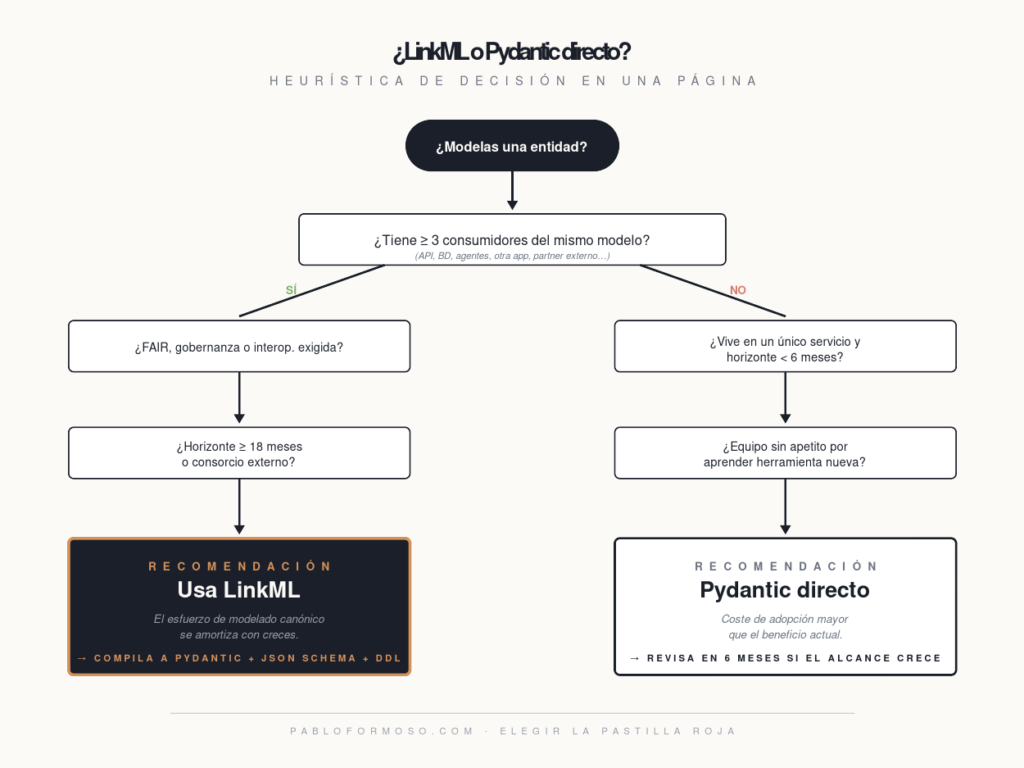
Usa LinkML cuando se cumplen una o varias de estas condiciones:
- Tienes tres o más consumidores del mismo modelo (API, BD, agentes, otra app).
- Hay requisitos explícitos de FAIR, gobernanza o interoperabilidad.
- El proyecto tiene horizonte largo (≥18 meses).
- Compartes el modelo con un consorcio externo o un cliente que exige semántica formal.
Quédate con Pydantic directo cuando:
- El modelo es interno, vive en un único servicio y nadie más lo consume.
- El proyecto es corto y no va a evolucionar mucho.
- Tu equipo no tiene apetito por aprender una herramienta nueva ahora mismo.
LinkML brilla en proyectos con múltiples bocas comiendo del mismo plato. Para una cuchara y un plato, sigue siendo overkill.
Riesgos honestos
Para no quedarme en el modo «venta»:
- Sesgo biomédico del ecosistema: las plantillas y ejemplos están dominados por dominios biológicos. Generalizar a industrial o empresarial requiere validación propia.
- Curva de aprendizaje semántica: conceptos como IRI, JSON-LD context o SHACL pueden intimidar. La buena noticia es que se pueden ignorar hasta que hagan falta. La mala es que la documentación tira a vocabulario ontológico.
- Bus factor moderado: el proyecto vive principalmente en LBNL/Monarch. No es Apache Foundation. Conviene tener un fork interno espejado.
- OntoGPT con modelos abiertos: SPIRES está validado contra GPT-3/4. Su rendimiento sobre Qwen o Mistral on-premise hay que medirlo. Suposición razonable: funciona, pero requiere tuning de prompts.
Mi recomendación práctica
Si me preguntas qué haría en los próximos dos meses con esto, mi respuesta tiene tres pasos pequeños y baratos:
- Spike de 1–2 sprints: coger un pipeline interno que ya tiene Pydantic + JSON Schema + SQLAlchemy duplicados y reescribir esa fuente común en LinkML. Medir fricción real.
- Piloto OntoGPT + Qwen on-premise: probar el patrón SPIRES sobre un dominio no biomédico, con extracción estructurada no trivial. Comparar contra una baseline manual.
- Documentar un criterio de uso interno de una página. «¿Cuándo LinkML, cuándo Pydantic?» — para que el equipo no tenga que reinventar el juicio cada vez.
Si los dos primeros pasos salen bien, LinkML deja de ser una curiosidad académica y se convierte en pieza arquitectónica transversal. Si salen regular, hemos perdido seis semanas y hemos aprendido algo. Coste asimétrico, riesgo controlado.
Cierre
Llevo unos años pensando en lo mismo: que los datos en las organizaciones tienen un problema de esqueleto, no de músculo. Compramos herramientas (músculos) constantemente, pero seguimos sin tener un hueso común que las sostenga. Cada decisión de arquitectura repite la misma tarea cognitiva: «¿cómo represento esta entidad?», «¿en qué formato?», «¿con qué validación?».
LinkML no es la única respuesta posible, pero es de las más serias que he visto. Y, sobre todo, es de las pocas que viene del mundo de la investigación abierta, con licencia permisiva y adopción institucional europea. Eso, en el momento en que estamos —con cada vez más presión por la soberanía de datos—, no es un detalle menor.
Si tu organización está construyendo agentes, extracción estructurada con LLM o data platforms que tienen que hablar con otros sistemas, vale la pena un spike. Como mínimo, vas a salir con un mapa mental nuevo sobre cómo separar la definición del dato de sus muchas representaciones.
Y eso, por sí solo, ya cambia bastantes cosas.
Fuentes
- linkml.io — sitio del proyecto
- github.com/linkml/linkml — repositorio core
- monarch-initiative/ontogpt — OntoGPT
- Moxon SAT et al., LinkML: an open data modeling framework, GigaScience 2026;15:giaf152 · DOI: 10.1093/gigascience/giaf152
- Caufield JH et al., SPIRES: Structured Prompt Interrogation and Recursive Extraction of Semantics, Bioinformatics 2024, btae104
Deja una respuesta