The itch that started it all
In late February 2026 I did something trivial: a script that took four lofi WAVs, stitched them together with a pydub crossfade and exported them to MP4 with a waveform in the background. The first commit in the repository is literally called yup. It had no agents, no catalog, nothing. It was a study session for myself.
But the experiment made two things very clear — and very unpleasant.
First: chaining two songs well is not a macro. If you glue two tracks together in different time signatures, with incompatible keys or mismatched BPMs, you don’t get "a mix". You get a crash. A linear crossfade applied to two signals at 0 dBFS adds up to +6 dBFS — out of range — and produces digital distortion. Without a pre-mix gain of −3 dB and peak monitoring, the final file clips.
Second: musical decisions don’t fit into a single prompt. "Make me a dark techno session" looks like an atomic instruction, but underneath it there are five different questions: which tracks from the catalog fit? in what harmonic order? is there an energy arc or is it all flat? which transitions are going to sound bad? is the final mix clean? A general-purpose LLM answers all five at once and none of them seriously. It sounds plausible and, musically, it’s flat.
From that itch — I want mixes that don’t crash, and a single agent can’t make them for me — everything else follows.
v0.x: the first pipeline (March)
On March 15 and 16, two commits appear that change the shape of the project: Initial public release — deep session generator and Add smart session generation with unified track catalog. The idea was simple but no longer trivial: separate the WAVs by genre folder, compute BPM with librosa and key in Camelot notation once per file, and store it all in a tracks.json serving as the single source of truth.
From that catalog, a selection function clusters by tempo and does a harmonic random walk over the Camelot wheel. The elegant thing about the Camelot wheel — developed by Mark Davis in 2004 — is that it reduces all of harmony theory to a neighbor graph:
def _camelot_neighbors(key: str) -> set[str]:
num = int(key[:-1])
letter = key[-1].upper()
opposite = "B" if letter == "A" else "A"
return {
key,
f"{(num % 12) + 1}{letter}", # +1 clockwise
f"{((num - 2) % 12) + 1}{letter}", # -1 counterclockwise
f"{num}{opposite}", # parallel key
}Two tracks are compatible if they sit at the same number, one clockwise position away, or in their parallel major/minor. That’s it. The computer does in milliseconds what a human DJ resolves through accumulated intuition.
With that I already had sessions that sounded "fine" — but the decision of which tracks to propose, in what order and for what mood was still monolithic. The thing was begging to be broken apart.
v1.0: the pantheon starts talking (April)
On April 7, ApolloAgents proper is born. With the release came four decisions that still hold the whole project up.
Decision 1 — agents with narrow roles, not a super-LLM. The session is decomposed into an 8-phase pipeline, each one handled by an agent with a specific system prompt, a closed list of tools and a structured output format. Each one carries a mythological name. Not out of aesthetic whim — because it forces you to think about their role before their implementation:
| Agent | Name | Function |
|---|---|---|
| Genre Guard | Janus | Confirms genre, duration and mood before planning anything |
| Catalog Manager | Hermes | Syncs WAVs, detects BPM and key |
| Planner | Muse | Proposes the playlist and designs the energy arc |
| Critic | Momus | Cold review: PROBLEMS / VERDICT |
| Editor | (REPL) | Permutes, moves, inserts bridges, kicks off the build |
| Validator | Themis | Analyzes the quality of the rendered audio |
| Orchestrator | Apollo | Conducts the sequence and keeps the memory |
Apollo is not a decorative name: he’s the conductor of the choir. As in the Greek pantheon, each deity owns a piece of the world. Janus looks in two directions — toward the user and toward the catalog — before letting anything through.
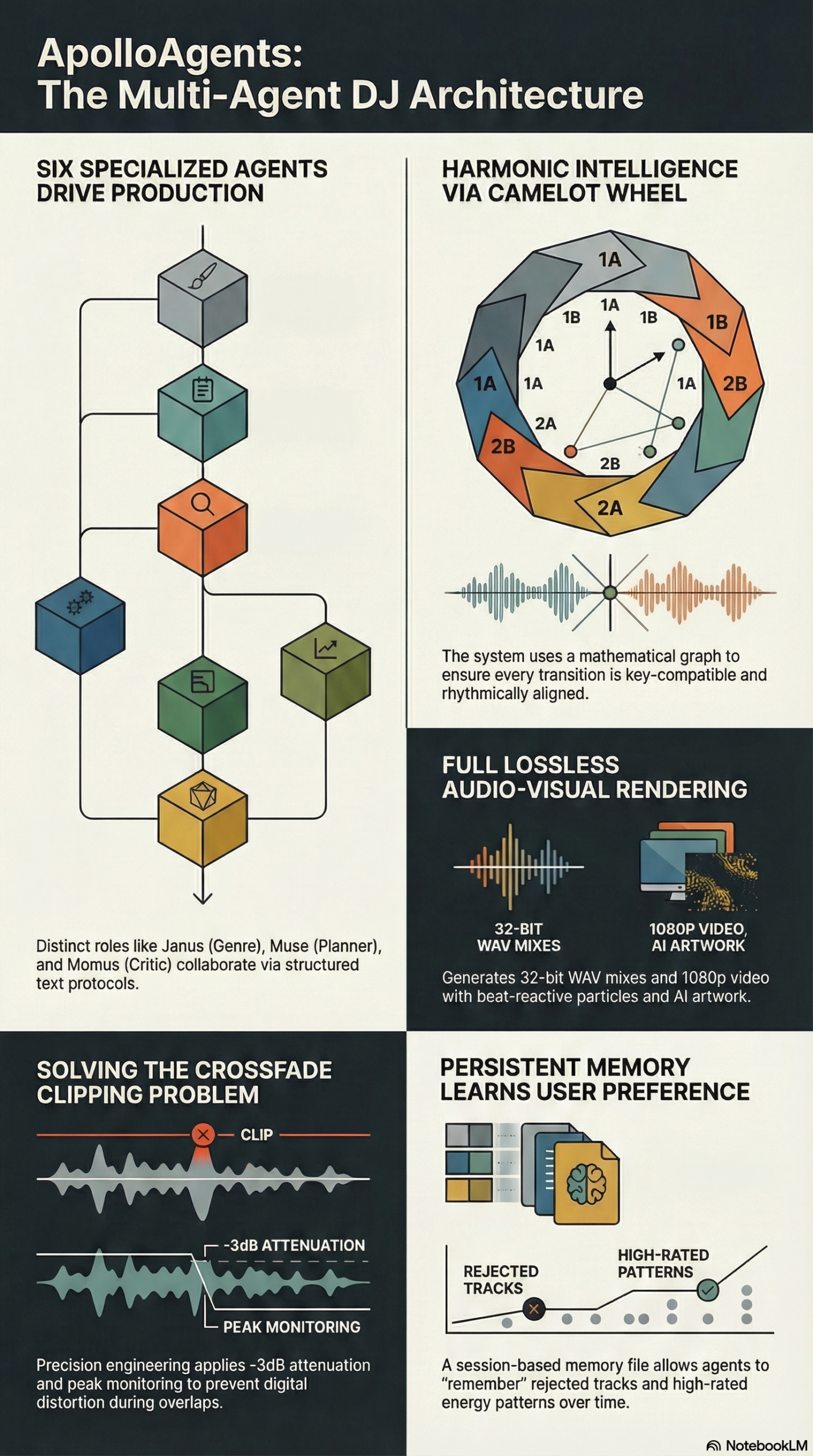
Decision 2 — structured-text protocols, not JSON. Asking an LLM to produce JSON between agents is fragile: the model makes up commas, sticks prose before the block, escapes quotes badly. ApolloAgents uses text blocks with sentinel keywords. Janus answers like this:
CONFIRMED
genre: techno
duration_min: 60
mood: dark industrial build to a hard peakAnd Momus like this:
PROBLEMS:
- [pos 2→3] key clash 5A → 11A — fix: swap pos 3 for a 6A track
- [pos 7→8] BPM jump 132 → 148 — fix: insert bridge track
VERDICT: NEEDS_FIXESThe parser is a line-by-line iteration of a few dozen lines of Python. If the model adds prose, it doesn’t break. If it strays from the format, there are fallbacks. It’s ugly in theory and rock-solid in practice.
Decision 3 — two human checkpoints inside the pipeline, not at the end. Full automation was tempting but wrong. Checkpoint 1 goes after the Planner and before the Critic. Checkpoint 2, after the Critic. Why two and not one? Because the questions are different: in the first one you’re shaping the energy arc; in the second, deciding which concrete problems are worth fixing and which ones to live with. Mixing the two conversations adds cognitive load and worsens both decisions. The checkpoints are hard gates: no agent applies a fix without your explicit go-ahead.
Decision 4 — a single main.py of ~2,600 lines. This remains controversial and I keep defending it. For a project of this scope, a single inspectable file with well-marked sections is more maintainable than a hierarchy of modules you have to hop through to understand a three-line change. The agent layer (agent/) does live separately — because its iteration cycle (prompts, tool signatures, memory schema) is of a different nature than the DSP pipeline‘s.
v1.1–v1.3: polishing the sound, not the layers (April)
By late April the system worked but was still doing two things badly. Each one spawned a mini-cycle of improvements.
Durations were estimates. The Planner computed the session length assuming 5 minutes per track. For a 60-min session it asked for 12 tracks and reality could come out at 50 or 75. Solution in v1.1: read duration_sec from the WAV header once when building the catalog, store it in tracks.json and use it for all subsequent calculations. Cost: zero decode. Benefit: the promised duration and the delivered one get close.
BPM detection lied on lofi. Librosa tended to detect all lofi at 110 BPM because of the classic octave problem (taking the off-beat for the beat and doubling the tempo). v1.1.1 fixes detect_bpm() to bias start_bpm toward the genre’s midpoint and try bpm/2 and bpm*2 before clamping. Result: lofi now gets detected at 70–85 BPM, which is what it should be.
Extreme crossfades sounded like a grinder. Pyrubberband starts producing audible artifacts at ratios above 1.5×. Before, if the Planner placed a 90 BPM track followed by a 140 one, the system tried to stretch it and the result sounded like a worn-out cassette. v1.3 introduced three mechanisms:
_STRETCH_MAX = 1.5— hard safety bound. Any transition requiring more gets flagged as a mandatory problem.suggest_bridge_track(from_pos, to_pos)— searches the catalog for a track with an intermediate BPM, scores it bymin(ratio_a, 1/ratio_a) × min(ratio_b, 1/ratio_b)and returns the 3 best candidates.insert_bridge_track(after_position, track_id)— inserts the chosen bridge, splitting one impossible transition into two individually safe ones.
And a fourth detail that changes the feel more than it seems: EQ matching in the crossfade. When the harmonic distance between two tracks is > 2 Camelot steps, a −3 dB high-shelf cut at 8 kHz is applied to the outgoing track and a −3 dB low-shelf cut at 250 Hz to the incoming one, only during the overlap. That reduces frequency masking without touching the audio outside the transition. It’s the kind of trick a mixing engineer applies by ear and which, once formulated, is half a dozen lines.
v1.4–v1.5: from batch to live (April)
By mid-April the agent knew how to build sessions but didn’t know how to listen to them. You could render a 60-minute MP4 without any way to preview a transition before committing to the full render. v1.4 brings in three tools that change the rhythm of the workflow: play_mix, preview_transition and play_track. Suddenly you can audit two overlapping tracks ±15s before deciding whether they’re chained well, without waiting through a 40-minute render.
But the real conclusion of that move arrived two days later, in v1.5: if you can play back, you can DJ live.
LiveDJ is a proactive agent with its own audio engine. While one track plays, another thread is time-stretching the next one with pyrubberband in the background, so that when the moment of the crossfade arrives the next track is already in memory at the correct BPM. The engine runs four threads:
| Thread | Cadence | Responsibility |
|---|---|---|
sounddevice callback |
Per block (2048 samples) | Low-latency audio output; crossfade mixing |
| Watchdog | 50 ms | Detects the threshold crossing and emits events |
| Pre-stretch daemon | Continuous | Stretches the next track with pyrubberband |
| Main event loop | 100 ms | Drains events and hands them to the LiveDJ agent |
The watchdog runs at twice the frequency of the agent’s event loop. That guarantees no critical event (threshold crossing, end of track) gets lost between two LLM polls. And the agent has a hard budget of 5 turns per batch of events — if it exhausts it without calling a terminal tool, the engine falls back to automatic behavior. Without that cap, an ambiguous situation could drag the agent into a chain of reasoning while the music keeps playing.
The decision rule LiveDJ applies as a crossfade approaches fits in three lines:
| Transition quality | Action |
|---|---|
| Camelot ≤1 step and ΔBPM ≤ 8 | Silence — let it pass |
| Camelot 2 steps or ΔBPM 8–20 | extend_track(20) — buys 20s to reevaluate |
| Camelot > 2 steps or ΔBPM > 20 | crossfade_now() or queue_swap() for something better |
And while it plays, you can type things like next, stay 60, more energetic or wind down. Some (the literal ones) execute without LLM mediation, for latency. Others (the natural-language ones) go through the agent so it translates them into tool calls.
v2.0–v2.6: opening the booth (April–May)
Until v1.5 everything lived in the terminal. v2.0 was the first big leap: turning each phase of the pipeline into FastAPI endpoints, opening a WebSocket channel for the agent’s streaming, and putting up a Next.js + React 19 client with a draggable playlist view and a Critic sidebar. print() dies; the typed event takes its place.
From v2.1 to v2.5 came thin layers, but loaded with details:
- v2.1 — beat-reactive visuals in the browser, with LiveEngine events bridged to the frontend as typed JSON.
- v2.2 — named playlists with CRUD + drag-and-drop reorder. Standardized development ports: 4010 frontend, 4020 backend.
- v2.3 — user_id propagated through the whole thread, per-track ratings and favorites, Planner bias based on the user’s own scores. The agents start developing an ear per person.
- v2.5 — the LiveEngine crosses into the browser: three modes (Audience, Booth, Immersive), a visual layer synced to the beat, and an improvisation mode with mic + audience requests.
And then, on May 11, v2.6.0 Ember. The previous frontend‘s 9-phase staircase collapses into five flat routes with a shared visual vocabulary — italic-serif, ember-red accent, a single command line:
/dashboard → tonight's session + the latest printed poster
/brief → one sentence in, a structured brief out
/curate → arc, playlist, critic's notes (apply / ignore inline)
/editor → reorder, swap, insert bridge tracks
/render → ffmpeg backend → 1080p MP4 with SSE progress
/live → real playback, Audience / Booth / Immersive modesThe brief gets parsed by Claude Haiku in under 300 ms into {genre, duration, mood, venue, energy, tempo}. If something is ambiguous, Apollo asks on the same screen and resumes when you confirm. The checkpoints still exist, but they stop being walls to cross phase by phase: now they’re annotations in the margin that you apply with a click or ignore.
v2.7–v3.1: the last mile (May)
In recent weeks the project has been moving in the space between "this works on my machine" and "this works live in front of people".
- v2.7 — ingestion of YouTube Live Chat as live audience requests. The audience types on YouTube, the engine reads it and the agent decides whether to factor it into the next decision.
- v2.7.2 — OBS feed, waveform peaks in the browser, YouTube polling that’s kinder to the API.
- v2.7.3 / v2.7.4 — robust live WebSocket reconnection, agent discipline, observability.
- v3.0 — precision beat matching offline and live with parity. Transitions latch onto real downbeats (detected with madmom) instead of approximations.
- v3.0.1 — a
critic_warningwhen the phase-lock can’t find the downbeat and falls back to the linear fade. Small change, big effect on trust: now you know when the system is improvising. - v3.1 — live beat matching with parity in the browser via
playbackRate. The tempo in the frontend‘s HTML5 audio matches the offline engine’s. What comes out of OBS sounds the same as what comes out of the render.
And one last detail from last week that changes everything for whoever comes new to the project: a Docker Compose stack with hot reload for both backend and frontend. docker compose up --build and you have it all running, without fighting uv or npm.
What I learned building this
There are three things I take away from the journey, and that I hold onto when starting new projects.
Narrow roles beat super-agents. It’s tempting to write a gigantic system prompt and let a single model "do everything". The experience with Apollo says the opposite: the narrower the role — Janus only validates, Momus only critiques, Themis only analyzes — the more predictable and debuggable the result. Modularity isn’t elegance: it’s the only way to know in which phase something broke.
Structured text eats JSON’s lunch between agents. Asking an LLM for blocks with sentinel keywords (CONFIRMED, PROBLEMS, VERDICT, Status:) and parsing them line by line sounds primitive. But it survives extra prose, badly escaped quotes, models that switch providers. JSON looked like the right answer and, in production, it wasn’t.
Humans at concrete checkpoints, not as final approval. The critic’s value is not enforcing the fix. It’s flagging the problem. The decision about what to fix — and what to live with — belongs to the user, and it has to live inside the pipeline, not after it. When I moved the checkpoints from "at the end, once" to "after the Planner and after the Critic", the quality of the sessions jumped at once.
ApolloAgents is open source under MIT, lives at github.com/pabloformoso/apollo-agents, and everything you see on this YouTube channel was generated by the system in one of its versions. If you try it — a star on the repo and, above all, whatever you find broken in the issues, would make my day.
Leave a Reply